Meta-pages: Toolkit tutorial¶
Uncertainty in models¶
Modelling is a vital part of research and development in almost every sphere of modern life. The objective of MUCM is to develop a technology that is capable of addressing all sources of uncertainty in model predictions and to quantify their implications efficiently, even in the most complex models. It has the potential to revolutionise scientific debate by resolving the contradictions in competing models. It will also have a radical effect on everyday modelling and model usage by making the uncertainties in model outputs transparent to modellers and end users alike.
Those who rely on models to understand complex processes, and for prediction, optimisation and many kinds of decision- and policy-making, increasingly wish to know how much they can trust the model outputs. Uncertainty and inaccuracy in the outputs arises from numerous sources, including error in initial conditions, error in model parameters, imperfect science in the model equations, approximate solutions to model equations and errors in model structure or logic. The nature and magnitudes of these contributory uncertainties are often very difficult to estimate, but it is vital to do so. All the while, for instance, different models produce very different predictions of the magnitude of global warming effects, with no credible error bounds, sceptics can continue to ignore them and pressure groups will seize upon the most pessimistic predictions.
Even if we can quantify all uncertainties in model inputs and structure, it is a complex task to derive appropriate measures of output uncertainty. One well-established methodology to address this problem of uncertainty analysis, or probabilistic sensitivity analysis, is to propagate input uncertainty through the model by Monte Carlo. However, this requires making typically tens of thousands of runs of the model, each with different randomly sampled inputs, and this is impractical for complex models. For any model that takes more than a few seconds of computer time per run, a thorough Monte Carlo sensitivity analysis becomes infeasible.
MUCM focuses on new methods which are orders of magnitude more efficient than Monte Carlo, requiring typically just a few hundreds of model runs, thereby providing very significant productivity gains for the researchers or analysis teams involved. Furthermore, these methods can address several related, but more demanding tasks that are of importance to modellers and model users, usually without requiring more model runs.
- Calibration and data assimilation. Calibration, the process of adjusting uncertain model parameters to fit the model to observed data, is typically a very demanding task that can involve many man months or even years of effort. Data assimilation, in which data are used to adjust the state vector of a dynamic model, is equally demanding and the subject of quite intensive research in its own right. MUCM methods can not only perform these tasks more efficiently, but also properly characterise how they reduce uncertainty about those parameters and state vector (and hence reduce uncertainty in model outputs).
- Variance-based sensitivity analysis and value of information. These are tools to explore how the model responds to changes in inputs, and the contribution that each uncertain input makes to the overall output uncertainty. They give modellers insight into how their models behave (often pointing to bugs in coding or model failures) and allow model users to prioritise research to reduce uncertainty.
- Validation and structural uncertainty. It is often said that models cannot be validated since no model is perfect. Nevertheless, it is possible to validate the combination of a model with a description of uncertainty, simply by computing implied probability distributions for test data and then verifying that they lie within the bounds of those distributions. However, this requires all forms of uncertainty to be accounted for, including uncertainty in model structure, and cannot be addressed by conventional Monte Carlo analyses. MUCM methods are able to tackle this problem, and indeed a model for model discrepancy underlies the calibration techniques.
Emulation¶
We refer to the process model to which MUCM methods are applied (and its implementation in computer code) as the simulator. The key to MUCM technology is the idea of an emulator, which is a statistical representation of knowledge and beliefs about the simulator. The emulator is not just a very accurate approximation to the simulator itself, but also incorporates a statistically validated description of its own accuracy. It is created using a set of runs of the simulator, in which the simulator outputs are observed at different points in the input space. This is called the training sample.
Emulator for a simple model based on 3 data points¶
Figure 1 illustrates how the emulator works in an extremely simple case. The simulator is supposed to be a function of a single input \(x\). Three training runs have been performed and the output computed at \(x = 1, 3\) and \(5\); these are the three points marked in the figure. The solid line is the emulator mean, which is a prediction of what the simulator would produce if run at any other value of \(x\). The dotted lines give 95% probability intervals for those predictions. Notice that the emulator interpolates the training data precisely and correctly shows no uncertainty at those points, but the uncertainty increases between training data points.
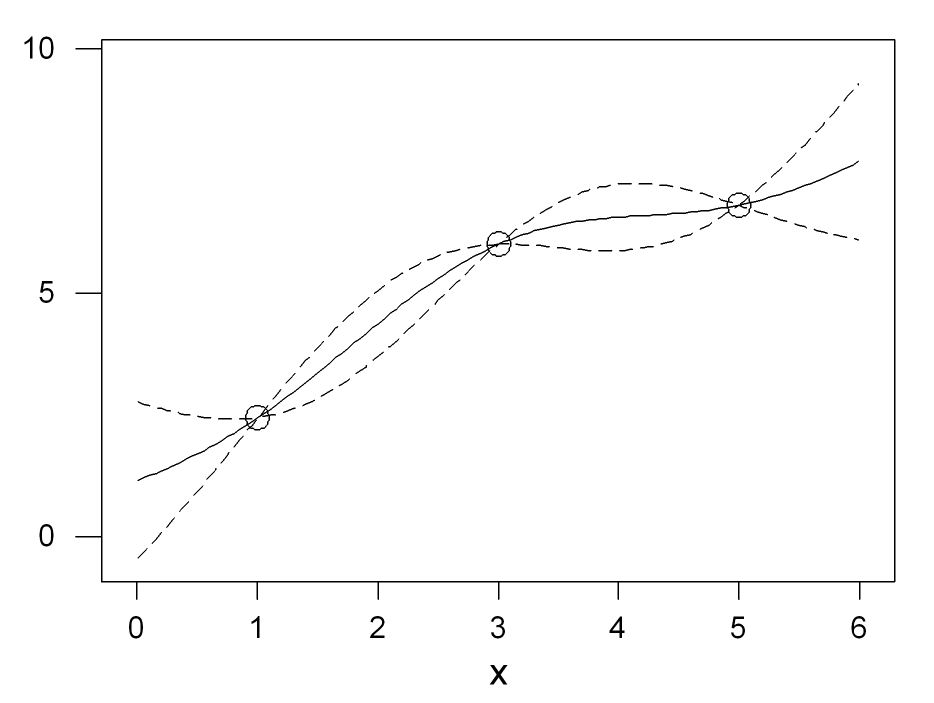
Figure 1: An example of an emulator fit so a small number of training points.
Figure 2 shows the same example after we add two more training runs. The emulator mean is adjusted to pass through the two new points, and the uncertainty is reduced considerably. Indeed, within the range of the training data the emulator now predicts the simulator output with very small uncertainty.
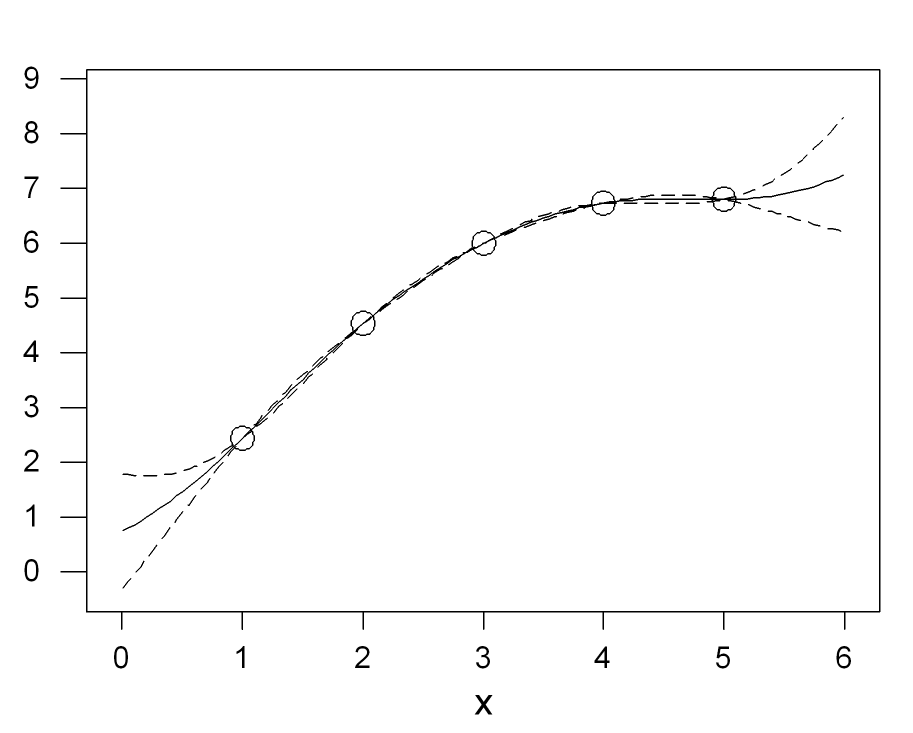
Figure 2: Additional points reduce the uncertainty of the emulator.
Properties of the emulator¶
The same features apply in any application with any number of inputs: the emulator reproduces the training data exactly, interpolating them smoothly with uncertainty that increases between data points. Increasing the number of training data points, so that they are closer together, in principle allows the simulator to be emulated to any desired degree of accuracy, with small uncertainty throughout the region of the input space of interest.
The emulator runs essentially instantaneously, making intensive exploration of the model and the consequences of uncertainty in inputs and model structure feasible for even highly complex models. Its mathematical form is also simple, so that in many cases the results of complex analyses of simulator output, such as sensitivity analysis, can be predicted analytically without needing to ‘run’ the emulator. In other situations, the analyses can be performed very much more quickly by running the emulator as a surrogate for the simulator, which may make feasible analyses that would otherwise be impossible because of computational intensity. Traditional approaches to tasks such as uncertainty analysis, particularly those based on Monte Carlo sampling in the input space, have been found in a range of applications to be orders of magnitude less efficient. That is, to achieve comparable accuracy those methods require tens, hundreds or even thousands of times as many simulator runs as MUCM methods based on emulation.
Toolkit issues¶
Although conceptually simple, the MUCM methods can be complex to apply. The role of the toolkit is to provide straightforward specifications of the MUCM technology. It is aimed at users of process simulators who wish to understand and manage the uncertainties in simulator predictions, and for other researchers in this field. Toolkit “threads” take the user step by step through building emulators and using them to tackle questions such as sensitivity analysis or calibration. In any application, a number of decisions need to be taken concerning questions such as the detailed form of the emulator; here are some of the principal issues that are addressed in toolkit pages.
- Type of emulator. In MUCM two different approaches to emulation are the fully Bayesian approach based on Gaussian process emulators and the Bayes linear approach which does not make distributional assumptions. The alternative approaches have advantages in different situations, but the principal distinction between them is a fundamental difference in how uncertainty is represented.
- Training sample design. The creation of a suitable training sample is a key step. This problem raises interesting new challenges for statistical experimental design theory. Although in principle we can emulate the simulator very accurately with a large enough training sample, in practice a large number of simulator runs is often impractical, and careful design is necessary to get the most out of a limited number of training runs.
- Fitting the emulator. Within the theory of the emulator are a number of optional features and parameters to be estimated. There are statistical and computational challenges here that are addressed in the relevant toolkit pages.
- Validating the emulator. The emulator may claim high accuracy in representing the underlying simulator, but is that claim justified? Validation uses a second sample of simulator runs to check the validity of the emulator’s claims.
- Model discrepancy. No model is perfect, and no simulator is a perfect representation of the real-world process it simulates. Techniques such as calibration rely on contrasting simulator outputs with real-world observations. It is vital to recognise that the real-world observations differ from the simulator output because of simulator error as well as observation error. An integral part of the MUCM technology is understanding model discrepancy.